Your RAG Pipeline is Probably Overkill
Note: This research was conducted in August 2025. Model capabilities and pricing move fast; some numbers (latencies, throughput, accuracy cliffs) may no longer reflect the current generation of models.
Six months of RAG optimization. Query rewriting got us from 60% to 65%, reranking to 68%, hybrid search to 70% accuracy extracting ESG metrics from annual reports (measured on a manually labeled evaluation set). Each trick bought us two or three points. Then someone asked: what if we just put the whole document in the context window?
We got 85%.
That question kicked off a research project that became a PyData 2025 talk. This post covers the key findings: when long context windows beat RAG, where they fall apart, and what you should actually do about it.
Tip:
- Under 100k tokens? Skip RAG. Context-only is simpler and performs as well or better.
- The 100k token quality cliff is real. Performance degrades sharply with distractors and dissimilar phrasing (per Chroma’s research).
- Reranking doesn’t improve answer quality in our experiments, even though retrieval metrics improve.
- Use way more chunks than you think. 50 chunks outperformed 5 or 10 significantly.
The problem that started it all
We needed to extract emissions data from annual reports for ESG analysis. Traditional RAG kept failing:
- Chunking destroyed cross-references between sections
- There was no standard ESG jargon across companies
- No good ground truth dataset existed for evaluation
Meanwhile, context windows were growing rapidly. In just two years, we went from 4k to over 1M tokens. An ABN AMRO annual report is around 500k tokens: it fits.
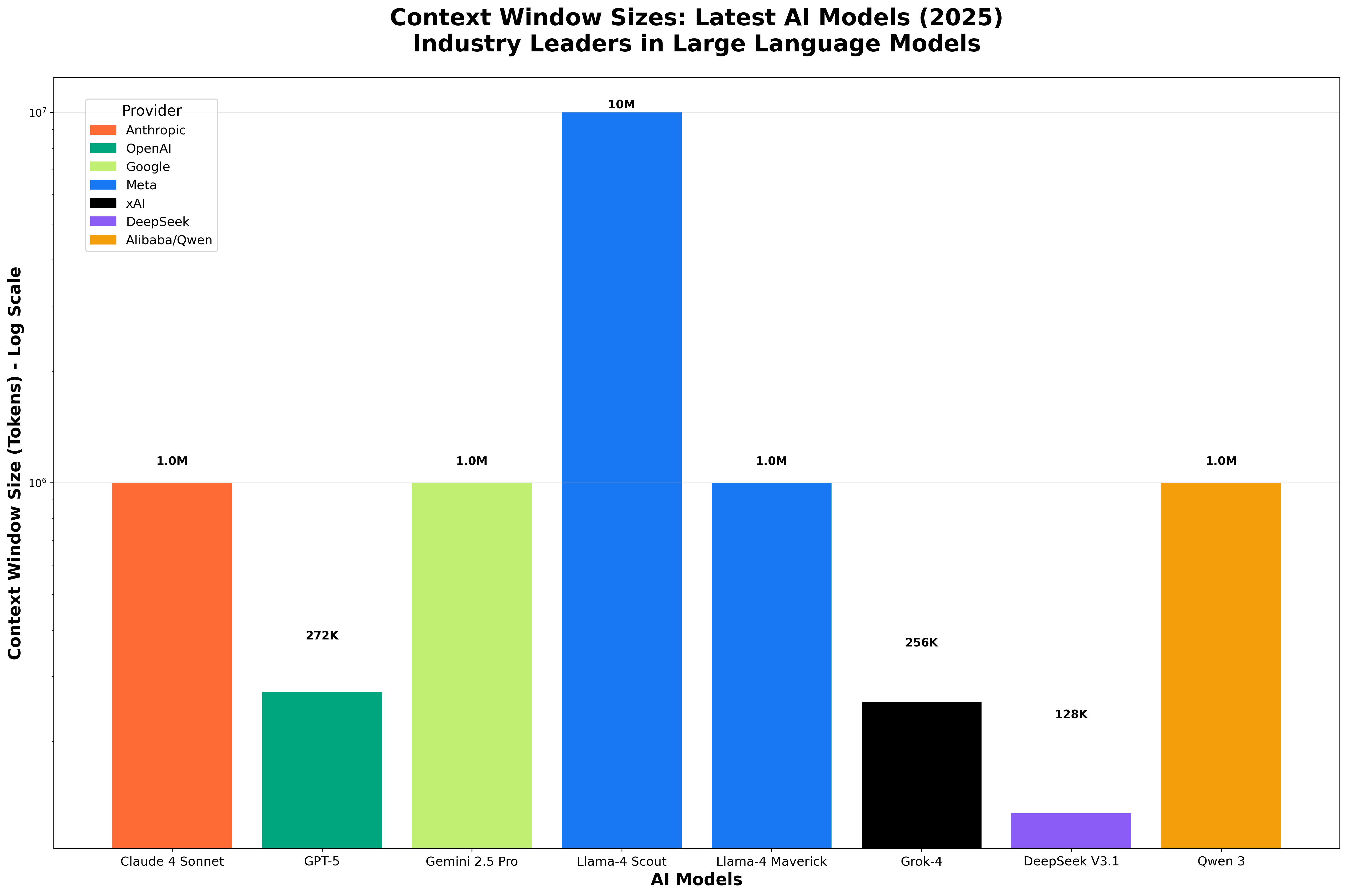
That growth isn’t monotonic, though. Gemini’s 2M window was quietly cut back to 1M. Llama-4 Scout advertises 10M tokens but Meta’s own API only serves 128k and third parties cap it at 1M. Claude Sonnet 4’s 1M window isn’t yet in general availability. The headline numbers are real, but availability lags the announcement.
The Lord of the Rings trilogy? That fits too. But as we’ll see, fitting in the context window and actually understanding all of it are very different things.
So the natural question became: can we skip RAG entirely and just put the whole document in the context window?
The research questions
This research, building on Chroma’s Context Rot study, set out to answer five questions:
- How fast are LLMs at processing large context windows?
- When can we skip RAG entirely?
- Where’s the performance cliff as context grows?
- Does reranking still matter for modern LLMs?
- Is long context worth the cost?
Let’s go through each one.
Speed: how fast are LLMs with large context?
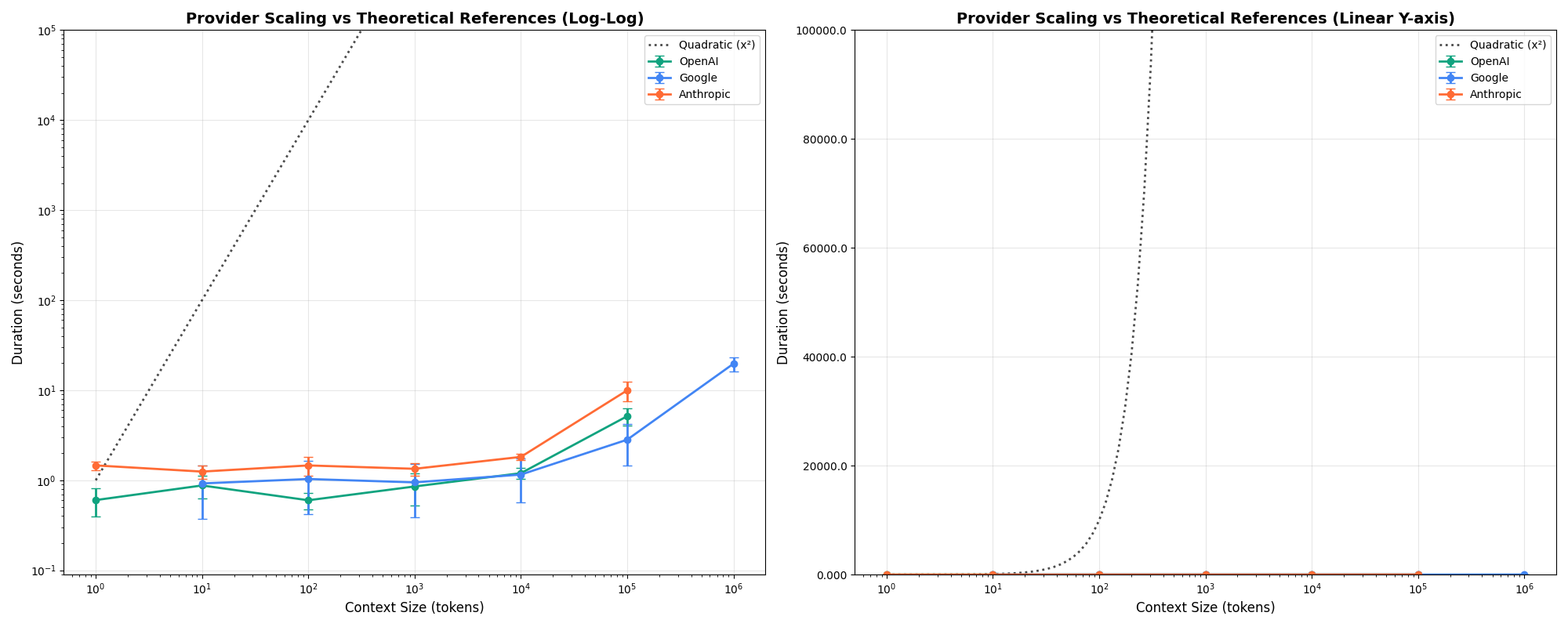
The common assumption is that attention scales quadratically with context length. Luckily, modern implementations do much better than that.
Speed benchmark setup. Six models tested via the orq.ai proxy:
gpt-5-mini,gpt-4.1-nano,gemini-2.5-flash,gemini-2.0-flash-lite-001,claude-sonnet-4-20250514,claude-3-haiku-20240307. Context sizes: exact powers of 10 (10, 100, 1k, 10k, 100k, 1M tokens), 3 iterations per point (108 API calls total). Prompts asked for a 1-2 sentence summary withmax_tokens=50, temperature=0. Haystacks were built from Paul Graham essays + ArXiv papers, shuffled at the sentence level, and trimmed character-by-character against thegpt-4otokenizer to hit the target length exactly. Caveat: the short output means these numbers are dominated by prefill, not generation — streaming UX will look different.
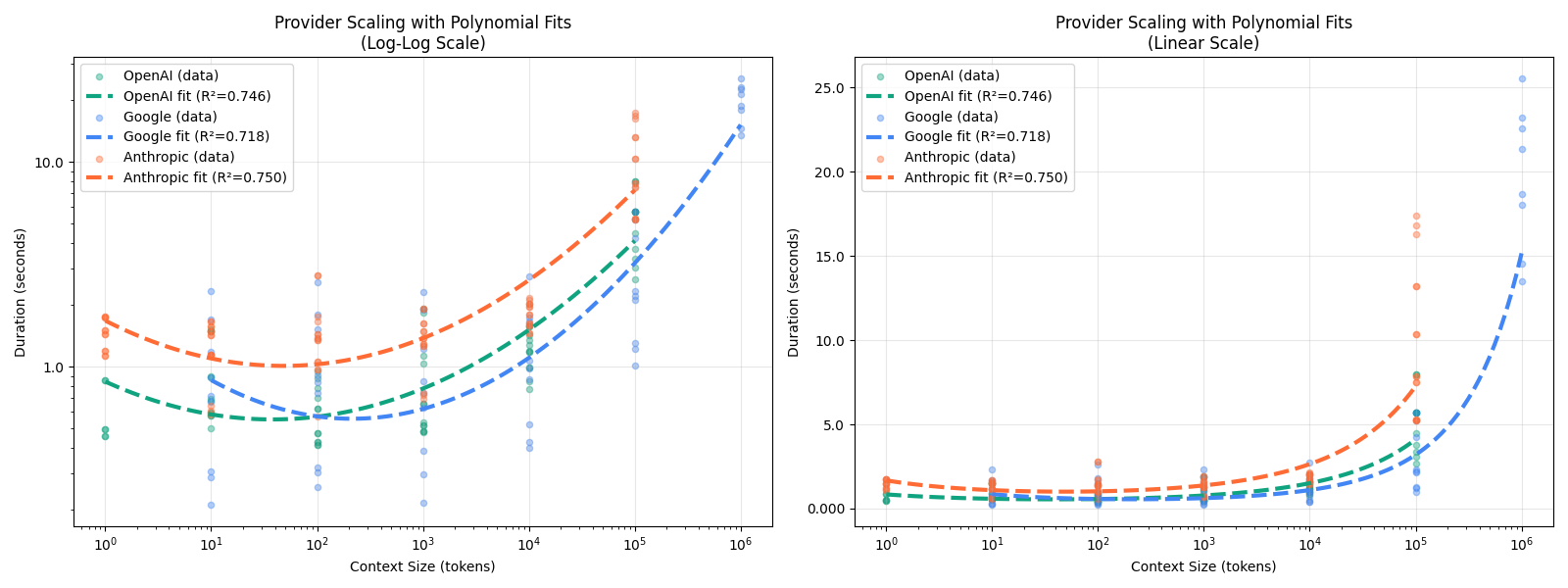
Latency starts climbing after 10k tokens
Across providers, there’s a clear inflection point around 10k tokens where latency starts increasing meaningfully. This is the speed threshold, distinct from the quality cliff at 100k tokens we’ll see later.
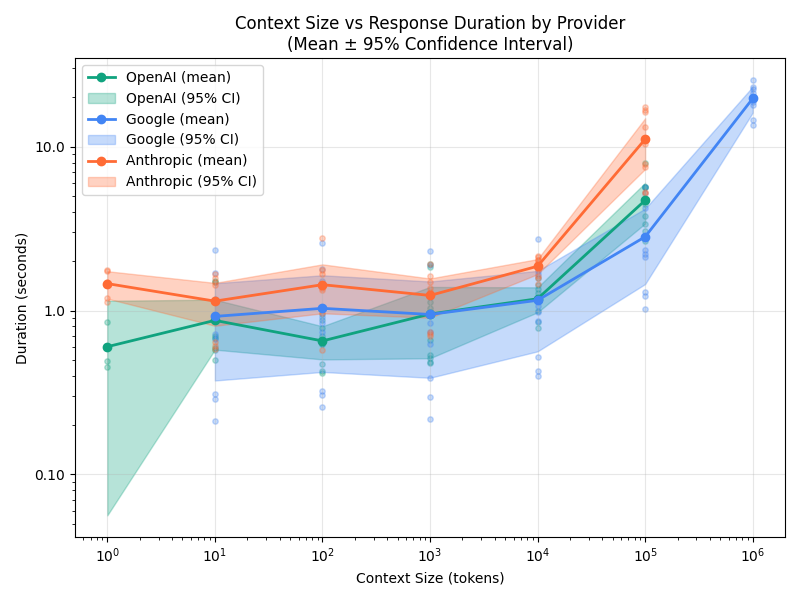
From 100k to 1M tokens, latency increases between 4x and 10x. At 100k tokens you’re looking at roughly 5 seconds; at 1M, that’s 20+ seconds.
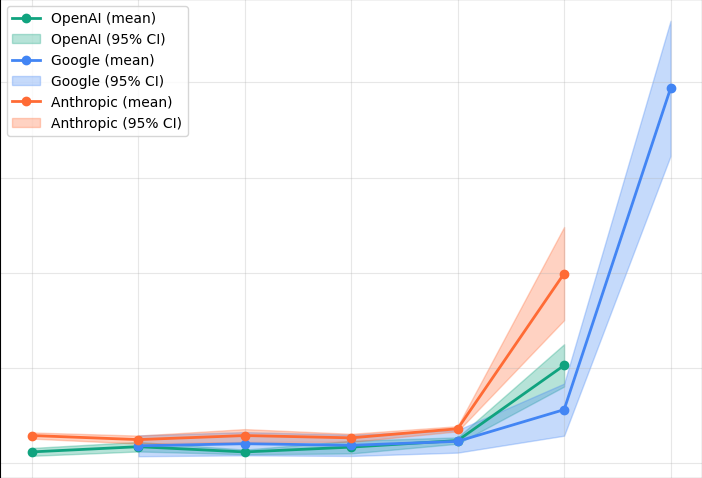
Time-to-first-token tells a similar story
If you’re streaming responses, TTFT is what your user actually feels. It tracks total duration closely — prefill dominates.
Fitting exponential curves to the per-provider data makes the scaling behavior easier to compare directly:
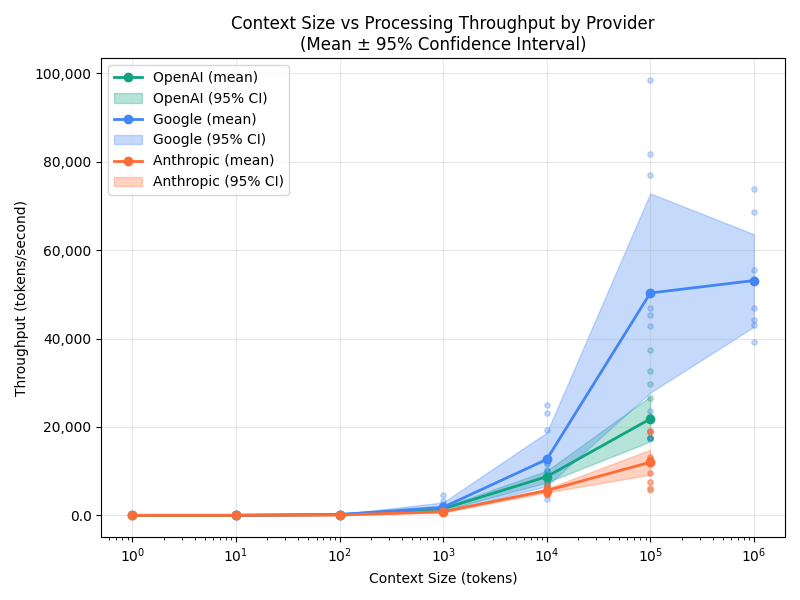
Token throughput flattens out
While latency increases, token throughput (tokens per second) holds relatively steady rather than collapsing. This suggests the latency increase is roughly proportional to context size, not quadratic.
Google’s three-tier speed system
Google deserves special mention here. Their model lineup (Gemini Flash Lite, Flash, and Pro) creates a well-differentiated tiered system where lighter models are genuinely faster and all reliably scale to 1M tokens.
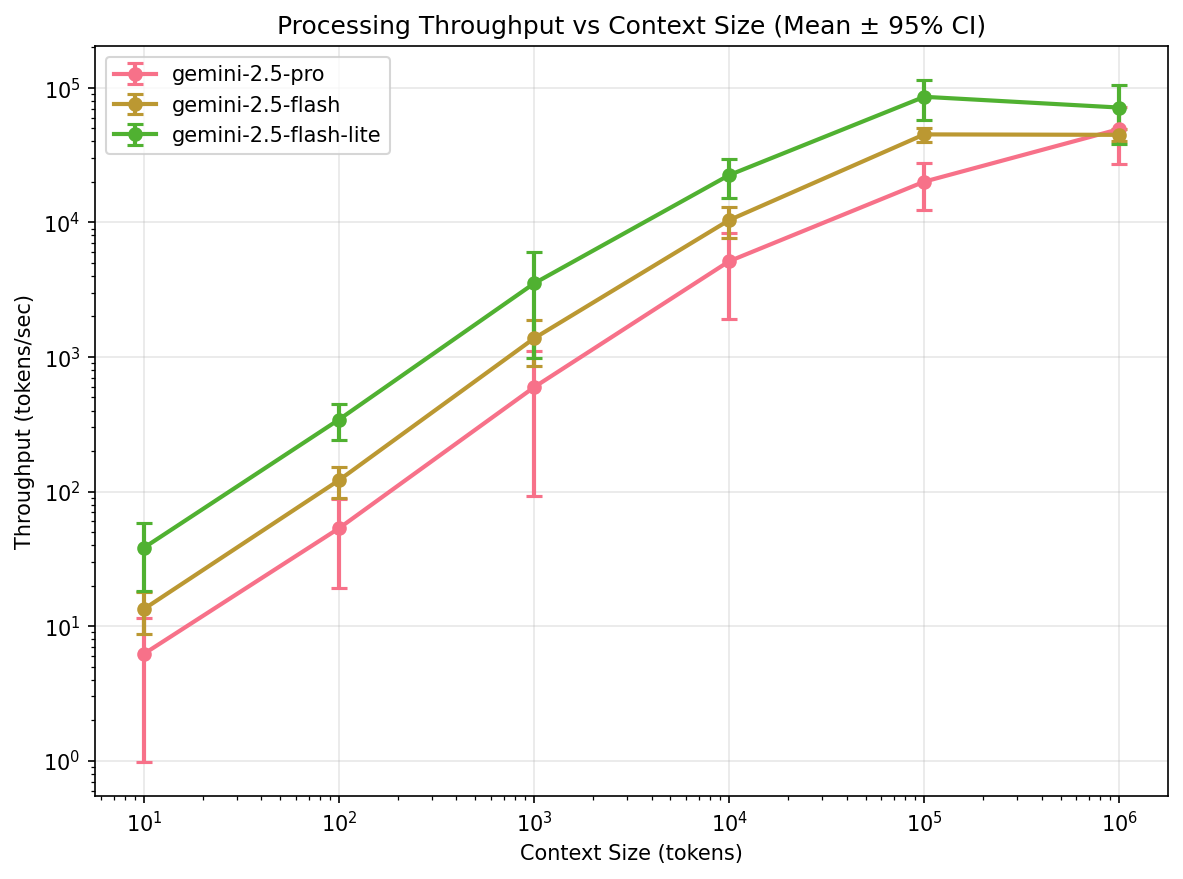
GPT and Claude don’t show this same clean tiering; their models cluster closer together in speed, with less predictable differentiation across context sizes.
Speed takeaways
- Scaling beyond 100k tokens is costly. Expect 4-10x latency increase
- Gemini is often the fastest for large context workloads
- It’s better than quadratic, but still significant
Quality: how well do context windows actually work?
The findings in this section come from Chroma’s Context Rot research, which goes well beyond standard benchmarks. I’ll summarize the key experiments here, but the full report is well worth reading.
Needle-in-a-Haystack (NIAH) benchmarks look great on paper. You insert a fact into a long document, ask about it, and models nail it. But how well do they work for non-trivial tasks?
Experiment 1: What happens when the needle doesn’t look like the question?
Standard NIAH benchmarks typically have high cosine similarity between the question and the inserted answer. Real-world scenarios often don’t. You might ask about “carbon emissions targets” and the answer is buried in a paragraph about “Scope 3 downstream value chain assessments.”
The Chroma team split needles into two groups based on embedding similarity:
- Similar to the query (easy mode)
- Dissimilar to the query (real-world mode)
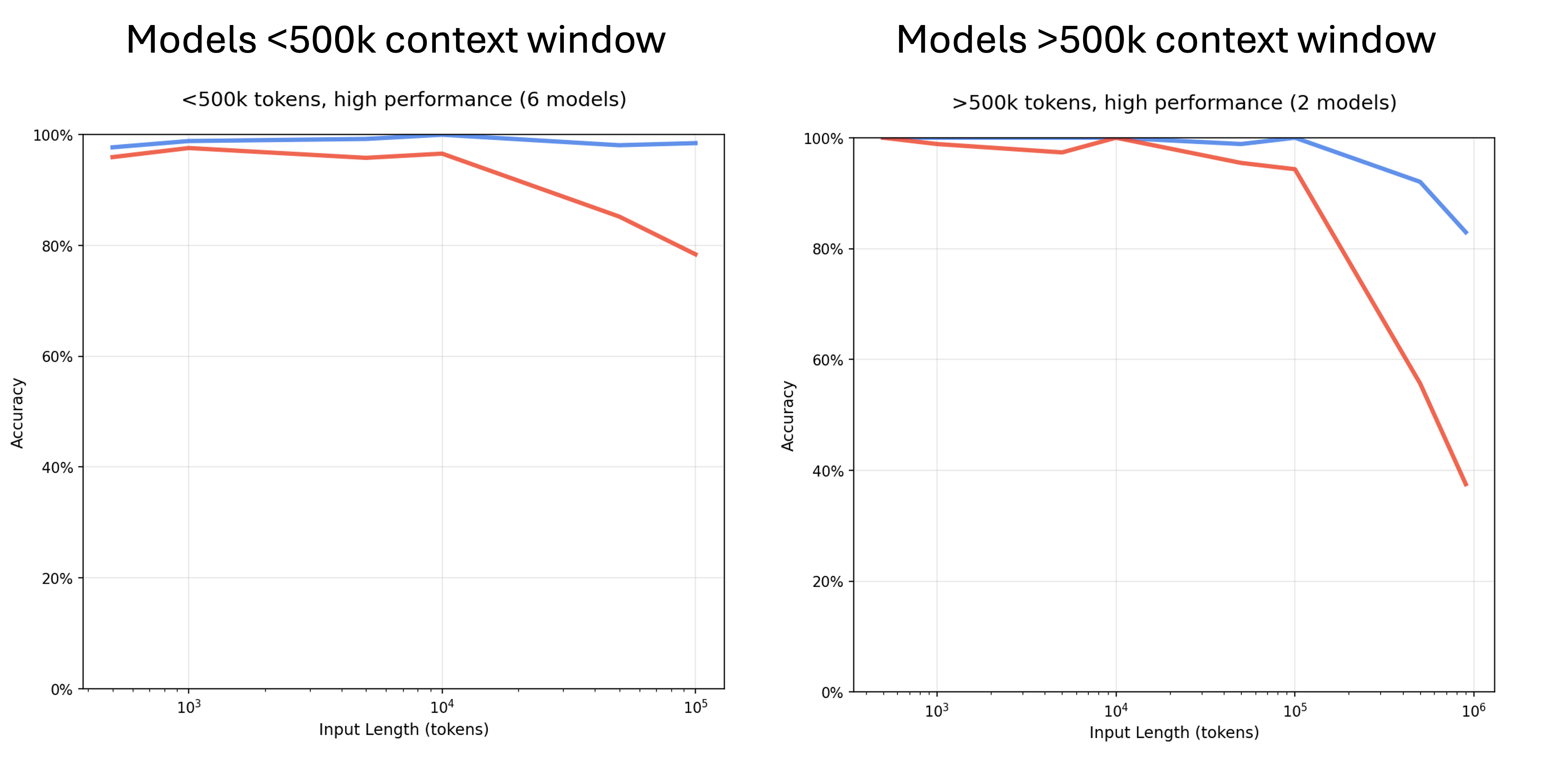
Key finding: Dissimilar question-answer pairs are challenging for all models, especially after 100k tokens. Smaller models degrade faster.
Experiment 2: The distractor problem
In real documents, there’s rarely just one relevant-looking passage. Consider a coding agent with 10 different versions of your updated function in the context window. Or an annual report where multiple sections discuss similar metrics in different contexts.
Context rot in the wild
If you’ve used Claude Code, Cursor, or any agentic coding tool on a long session, you’ve already seen this failure mode. The agent creates a v2 of a function, then a v3, then patches the original, then forgets which version is canonical. It writes a checkpoint file, then starts over from scratch the next turn. It does an incomplete grep, decides nothing exists, and reimplements what it missed. These aren’t bugs in the tool — they’re what happens when eight competing versions of “the right answer” sit in the same context window and the model picks whichever one is most salient right now. Which is exactly the distractor problem, just at production scale.
The Chroma team tested this with explicit distractors: passages similar to the answer but containing different (wrong) information.
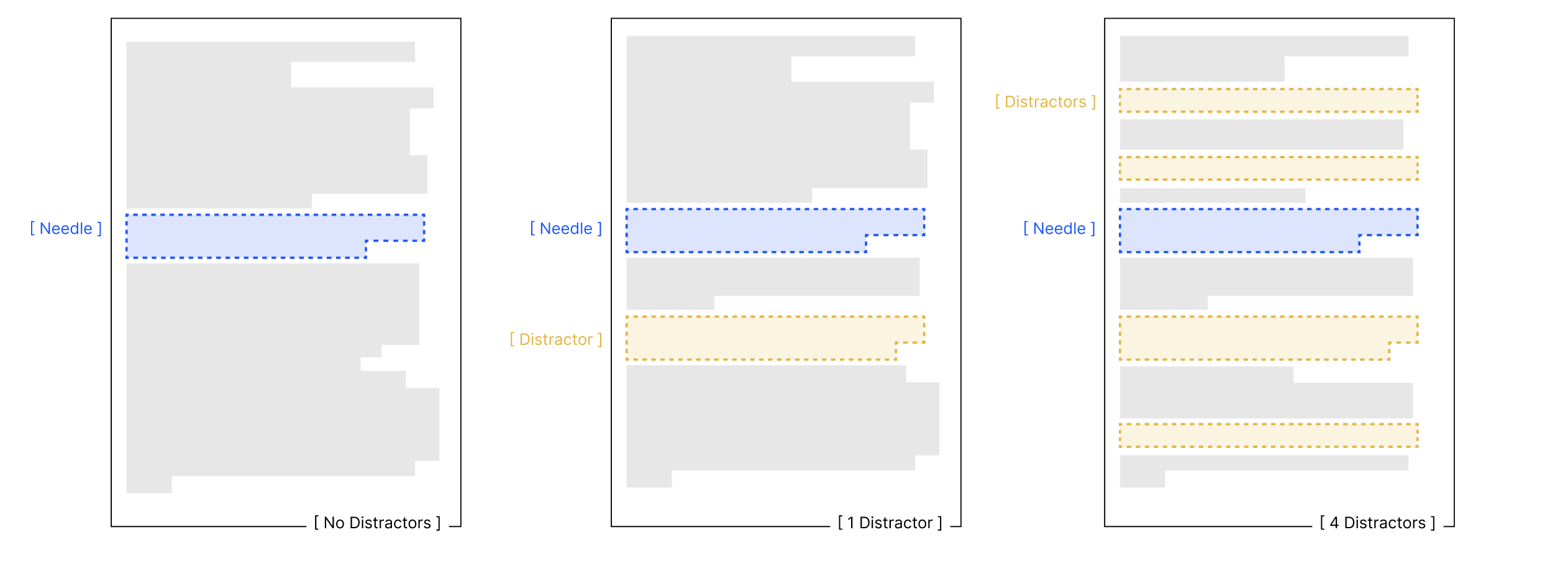
Question: What colour was the duck I had as a child?
Needle: The duck I had when I was 10 was orange.
Distractors:
- My brother’s duck was blue
- The duck I had as an adult was purple
- The childhood pig was pink
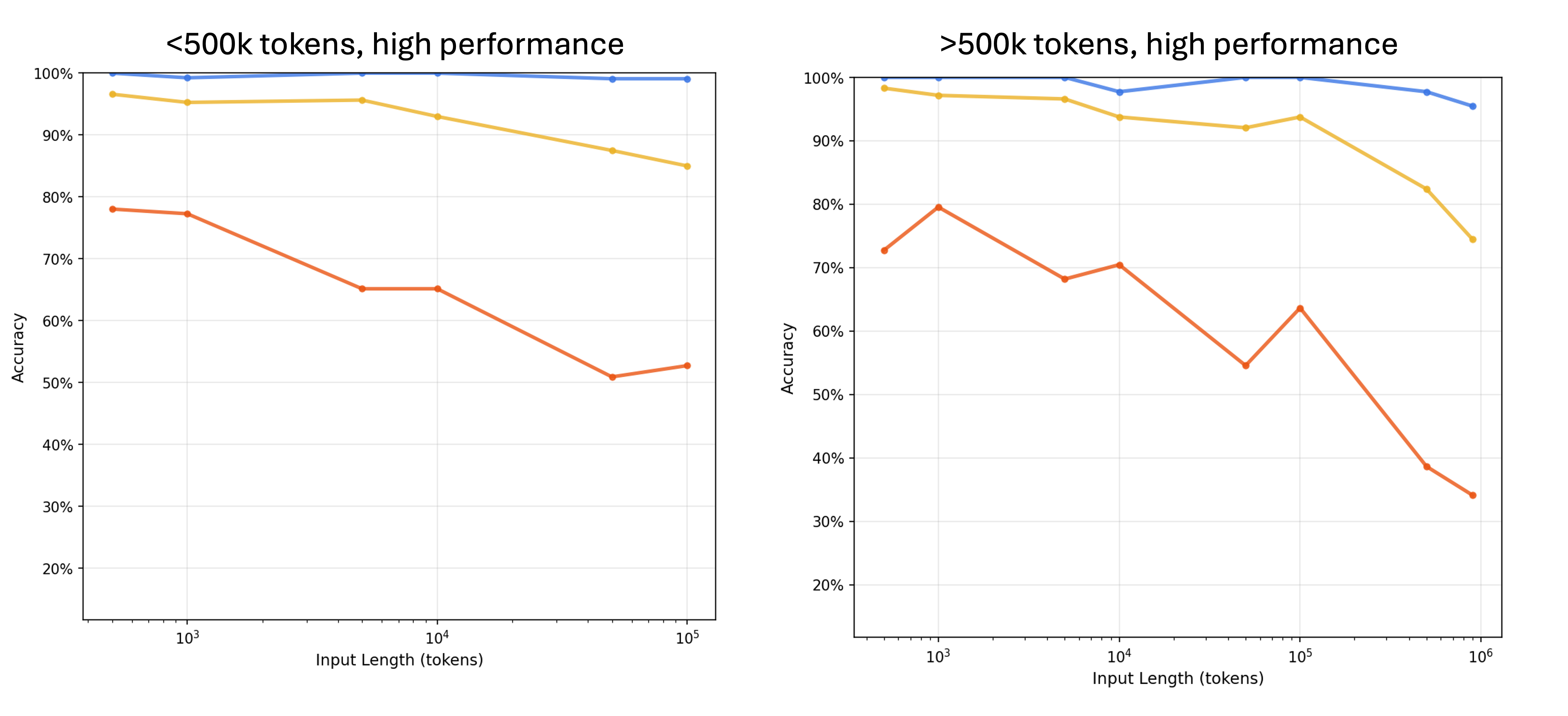
The results are unambiguous: more distractors mean worse performance across all models. Smaller models degrade fastest, and even a single distractor reduces performance relative to the baseline.
Failure modes differ by model family
Model families fail in different ways. Claude hallucinates the least, but this comes with a trade-off.
Experiment 3: Long conversational QA
For a more realistic test, the Chroma team used the LongMemEval dataset: 306 chat-based questions averaging ~113k tokens of context, compared against focused prompts with only ~300 tokens of relevant context. Questions span several types — single-session preference, temporal reasoning, knowledge update, multi-session, and more — which matters because full-context performance isn’t uniform across them.
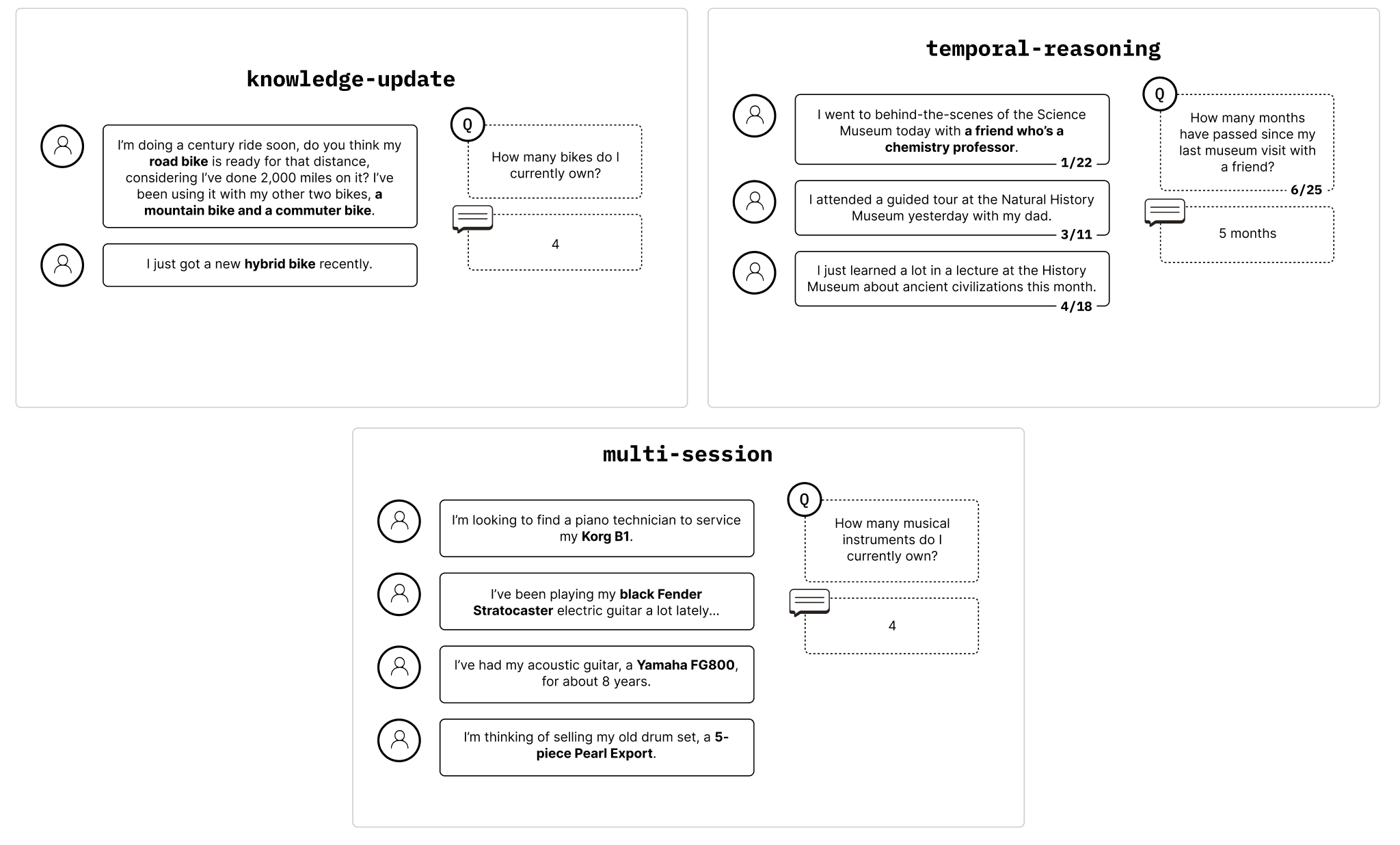
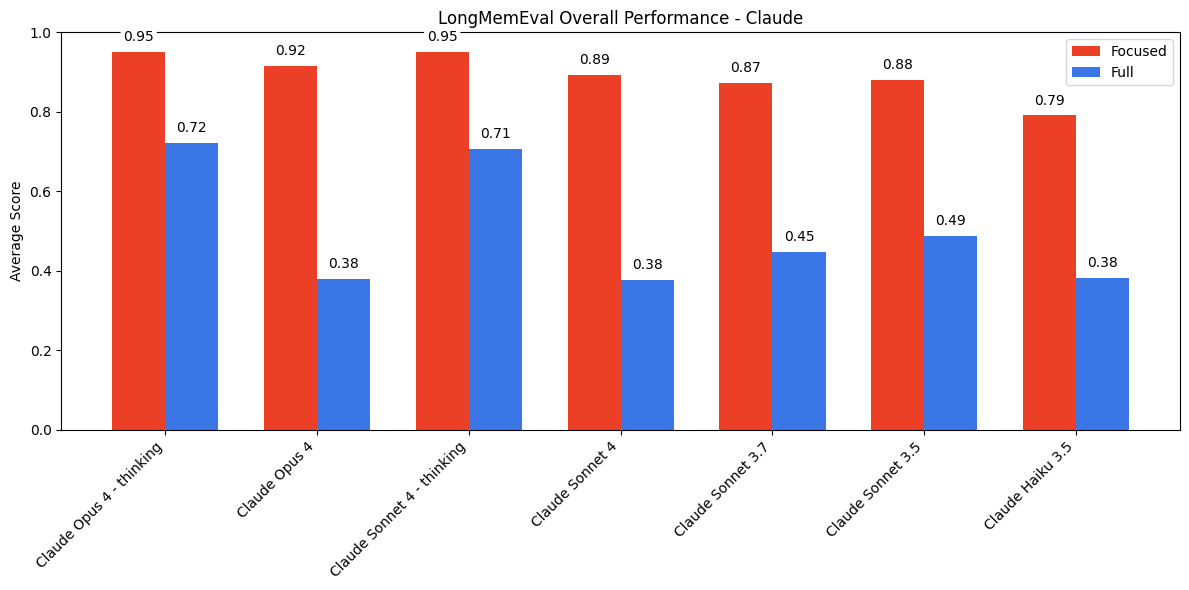
Claude refuses to answer when in doubt. Is this good or bad? It reduces hallucination but also reduces recall.
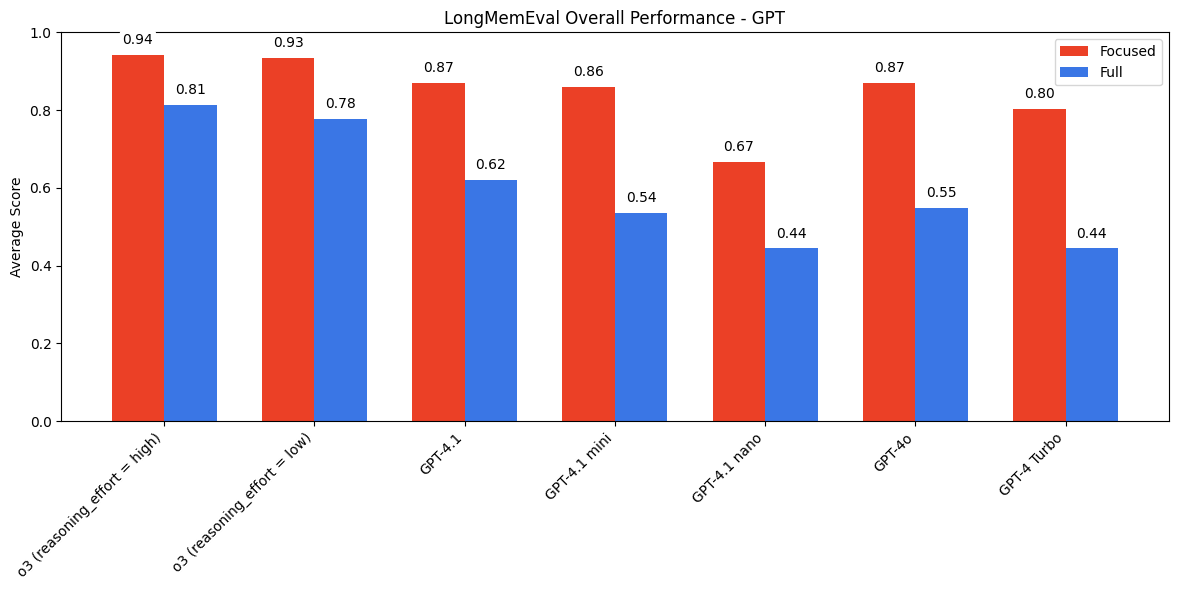
GPT sits in the middle — less cautious than Claude, less capable than Gemini with reasoning.
Gemini performed the best overall, especially when using reasoning capabilities.
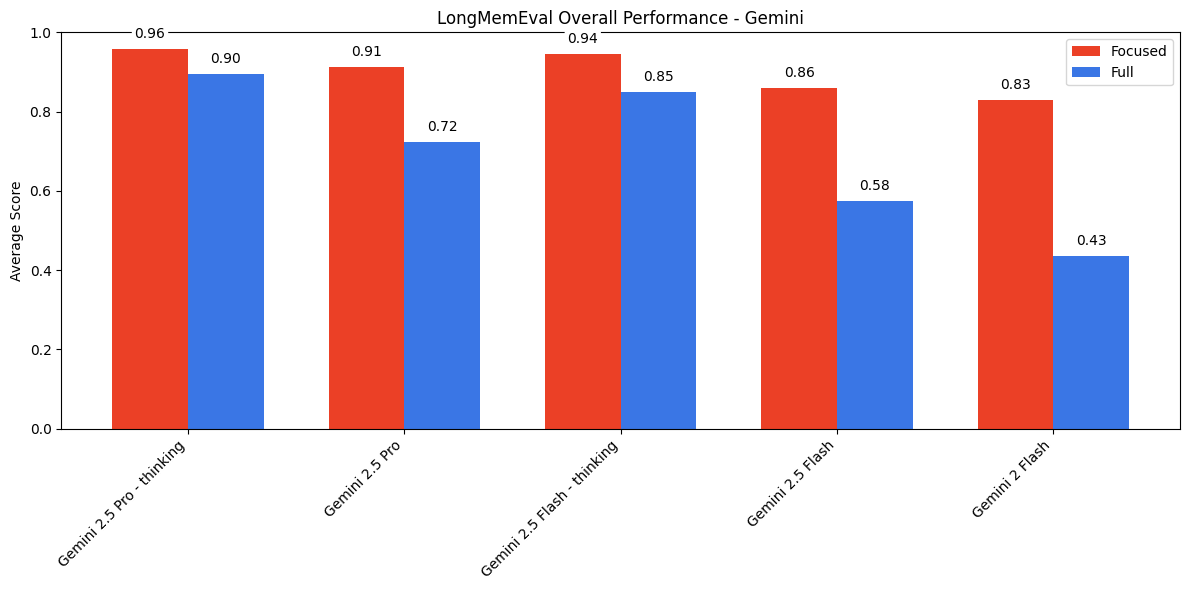
Quality takeaways
- Long context Q&A is very much unsolved, even at “only” 113k tokens
- Reasoning helps a lot (models with chain-of-thought do better)
- Hallucination prevention can backfire (Claude’s caution hurts recall)
- The 100k token threshold is where things start going wrong
Reranking: does it still matter?
Reranking has been a staple of RAG pipelines: retrieve broadly, then rerank to put the most relevant chunks first. But with modern LLMs handling noisy context better than ever, is it still necessary?
Experiment setup
We ran a full experiment:
- RAG types: Basic RAG and Enhanced RAG (LLM query rewriting + dual retrieval + Reciprocal Rank Fusion)
- Reranking: With and without, using
cross-encoder/ms-marco-MiniLM-L-6-v2 - Baseline: Full context window (no retrieval)
- Answer model: GPT-4.1-mini (temp=0,
max_tokens=500), prompt: “Answer the question based on the retrieved context.” - Embeddings:
text-embedding-3-small - Chunking: 500 tokens with 50-token overlap
- 200 questions grouped into context-size bins: 0–25k, 25–75k, 75–150k tokens
- 1 to 50 chunks retrieved per query
- 3 runs each,
~35,000 total datapoints
Ground truth came from the LongMemEval “focused” gold spans: for each question, we scored every chunk in ChromaDB (~50k chunks) against the gold span using Jaccard similarity (≥0.65 threshold), ROUGE-L, and token containment. Triangulating across three metrics is stronger than cosine-only and removes the “how did you label ground truth?” objection.

How we scored correctness
Every answer went through an LLM-as-judge (GPT-4.1, temp=0, structured Pydantic output) that produced two independent scores:
is_correct— is the answer right compared to the ground truth?is_correct_given_context— is the answer reasonable given what was retrieved?
The gap between the two is diagnostic. If is_correct_given_context stays high but is_correct drops, retrieval missed the relevant chunk. If both drop together, the model couldn’t use the context it had. This is how we know reranking isn’t helping generation — we can measure retrieval-quality and generation-quality separately.
You need more chunks than you think
The first surprise: hit rate (was the correct chunk even retrieved?) keeps climbing well past k=10 or k=20.

Performance saturates around 50 chunks, which is about 27% of the total chunks per document, and answer correctness plateaus near 92%. For reference, these documents averaged ~27k tokens split into ~181 chunks of ~150 tokens each; k=50 corresponds to roughly 20k retrieved tokens, or about 40–50 pages of text. That’s a lot more retrieval than the k=5 or k=10 that many tutorials suggest.
Reranking improves retrieval metrics but not answers
Here’s the surprising finding. Reranking clearly improves information retrieval metrics like MRR and Recall:


But when we look at what actually matters (did the model get the right answer?), reranking makes essentially no difference:

The same null result shows up if you slice correctness across RAG type × reranker × chunk count as a heatmap:

At least in our experiments, modern LLMs proved good enough at finding the relevant information in noisy retrieved context without needing it neatly sorted for them.
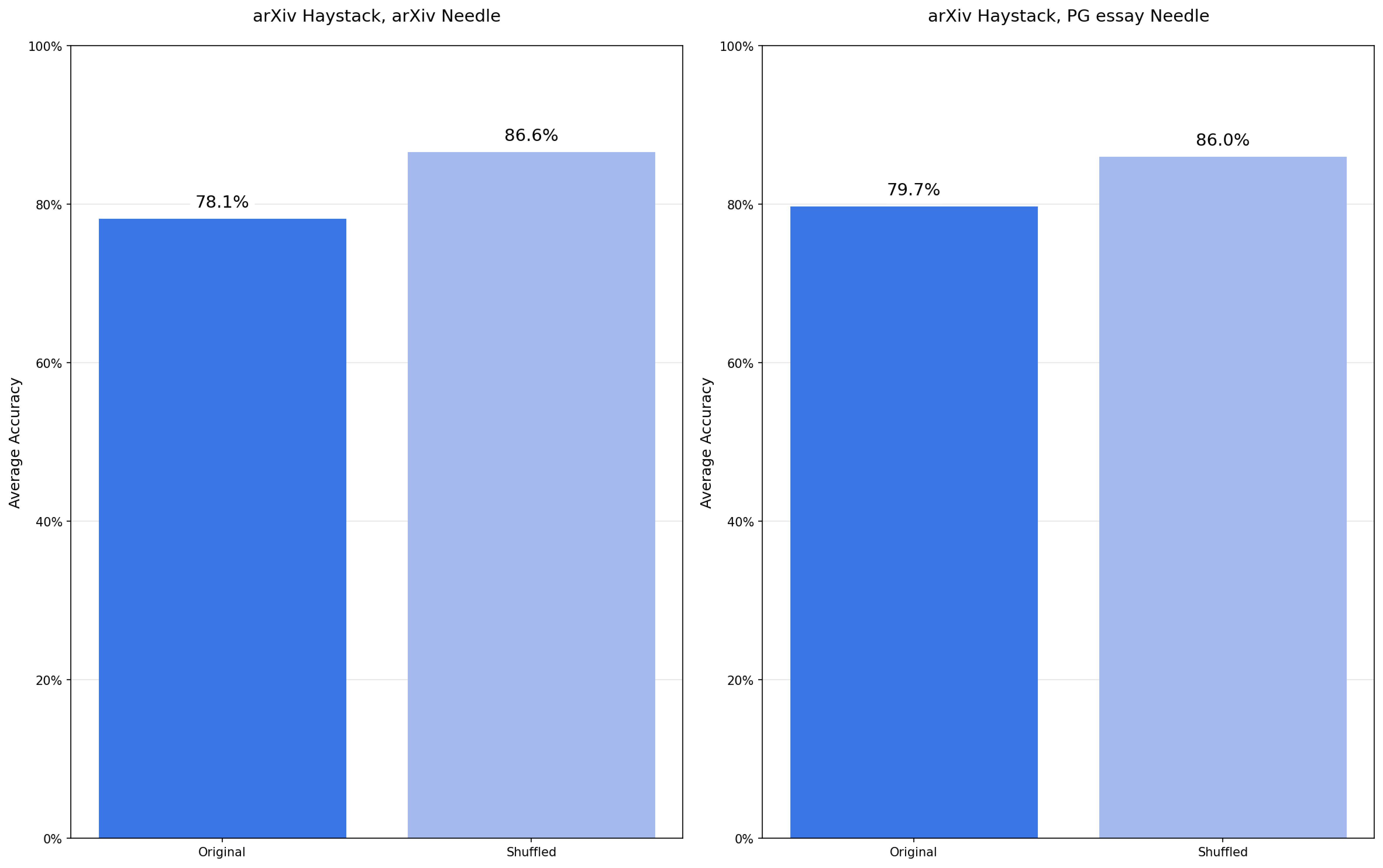
An adjacent surprise: shuffling sometimes helps
Since ordering doesn’t seem to matter the way the reranking story assumed, we also looked at what happens when you actively shuffle retrieved chunks. In several conditions it slightly improves correctness — consistent with Chroma’s observation that attention patterns vary by position and that “put the best chunk first” isn’t always the right prior.
Speed comparison
For documents in this size range (~27k tokens per document), the speed between RAG and full context was surprisingly comparable.
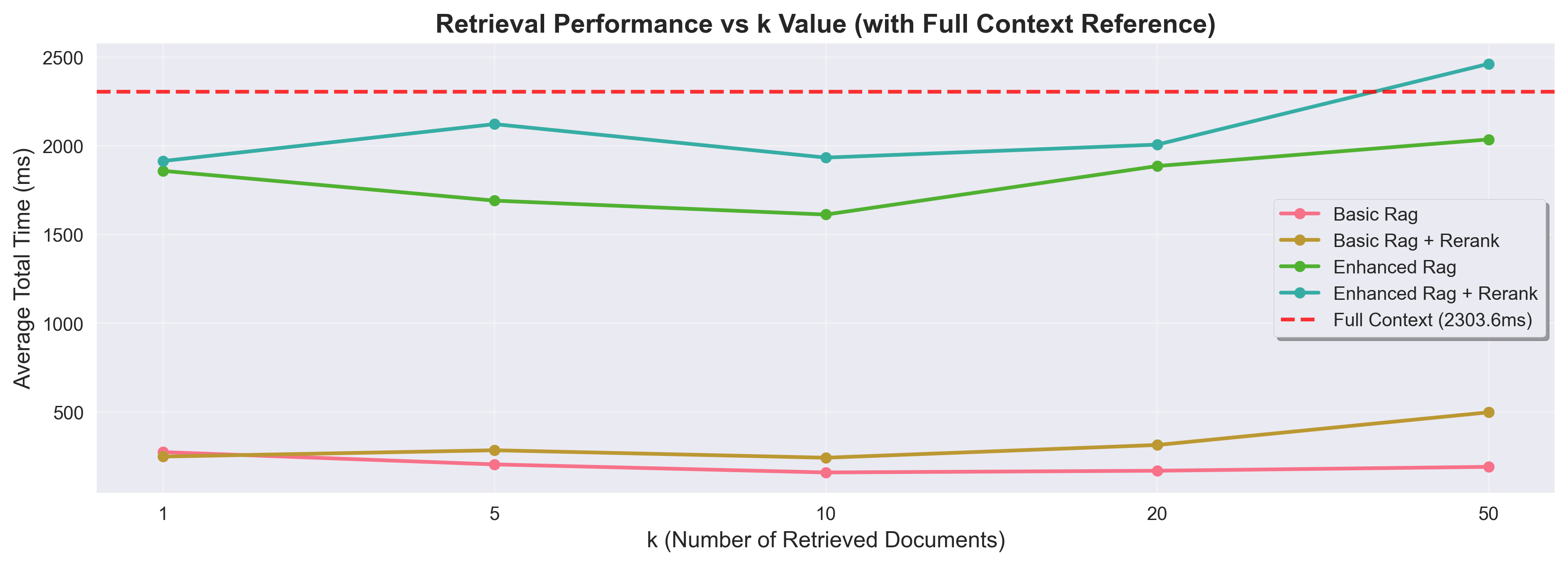
That said, this comparison is for single documents. RAG’s core advantage is scaling to large corpora, and that advantage grows with corpus size. More complex RAG pipelines will also be slower (query rewriting, reranking steps add latency), but their cost scales linearly rather than with the full corpus size.
RAG takeaways
- You need much higher K than you think. 50 chunks saturated performance in our tests
- In our experiments, reranking did not improve answer quality, even though retrieval metrics improved
- Speed is comparable between RAG and full context for small-to-medium documents
Limitations
Before you go ripping out your RAG pipeline, some caveats:
- Limited query complexity: mostly single-hop questions in our RAG experiments
- No reranking-as-filtering: we didn’t test using reranker confidence scores to filter chunks
- Limited scale: max 339 chunks per document
- Limited model diversity: a small set of models tested
- Single embedding model: only text-embedding-3-small
A practical decision framework
Based on these findings, here’s when to use what:
The 100k cutoff isn’t arbitrary. The Natural Questions dataset — a common realistic-QA benchmark — has documents averaging ~77k tokens with a stdev of ~55k. Most real QA documents land below 100k; the cliff is where they start to hurt.
Skip RAG when:
- Your domain fits in <100k tokens
- You have complex, multi-hop queries that need cross-referencing; chunking destroys these relationships even more than long context degrades them
- The simplicity gain of removing retrieval infrastructure matters to your team
Use RAG when:
- Your domain exceeds 100k tokens
- You’re dealing with simple, factual queries
- You need to search across a large corpus (RAG scales, context windows don’t)
And in both cases:
- If it fits in the context window, speed is likely comparable
- Use more chunks than you think (k=20-50, not k=5)
- Question your reranking step. It might not be helping
What to do Monday morning
- Audit your RAG pipeline. Is your domain under 100k tokens? You might not need RAG at all.
- Try context-only for small domains. The simplicity gain is massive.
- Crank up K. Run your existing eval set with k=50 and compare against your current k. The improvement may surprise you.
- A/B test removing reranking. Measure answer quality, not just retrieval metrics. If correctness doesn’t change, you can drop the complexity.
Acknowledgments
The context window quality experiments in Section 2 come directly from Chroma’s excellent Context Rot article. Their work was a major inspiration for this talk and this post. Thanks to orq.ai for providing unified LLM API access and observability that made running the speed and reranking experiments across multiple providers feasible.
The full code and experiment data are available on GitHub.
This post is based on my PyData Amsterdam 2025 talk “Context is King: Your RAG Pipeline is Probably Overkill.” If you have questions or want to discuss your own RAG challenges, feel free to reach out on LinkedIn.